Application of multiple regression for disease forecasting
In a simple linear regression, a response variable y is regressed on a single predictor (explanatory) variable x. In the context of disease forecasting, y might denote disease severity with x denoting a predictor like mean temperature. The model is y=β0+β1x+ε where ε is iid Normal (0,>σ2); see Sparks et al. (2008) for an introduction to linear regression with examples in R. Multiple linear regression generalizes this methodology to allow for multiple predictor variables, such as mean temperature and mean relative humidity. Notation for a model including m predictors is y=β0+β1x1+β2x2+...+βmxm+ε.
One common multiple linear regression model is the polynomial model:
y=β0+β1x1+β2x12+β3x2+β4x22+β5x1x2+ε.
The estimate of the parameter can be calculated by redefining variables:
w1=x1, w2=x12, w3=x2, w4=x22, w5=x1x2.
and performing a multiple linear regression model using
y=β0+β1w1+β2w2+β3w3+β4w4+β5w5+ε.
This now is an ordinary multiple linear regression model using w as predictor variables.
The goal of multiple linear regression may be accurate prediction, or the regression coefficients may also be of direct interest themselves (Maindonald and Braun 2003).
Example of Multiple Linear Regression using R
The function used to fit multiple regression models is the same as for simple linear regression models:
lm(formula,data)
The following example, using simulated data, is an extension of the example provided for simple linear regression (Sparks et al. 2008). Here the response variable is disease severity, and the predictor variables are temperature, relative humidity and rainfall amount. A review of the use of the R programming environment may be helpful (Garrett et al. 2007).
disease<-c(1.9, 3.1, 3.3, 4.8, 5.3, 6.1, 6.4, 7.6, 9.8, 12.4)
#response variable
temperature<-c(>62, 61, 65, 65, 80, 80, 83, 70, 90, 85)
#predictor variable
rel.humidity<-c(55, 57, 53, 52, 32, 34, 30, 45, 25, 36)
#predictor variable
rainfall<-c(1, 1, 0.5, 0.9, 0.1, 0.2, 0.8, 0.4, 0, 0.2)
#in inches
severity.mult <- as.data.frame(cbind(disease, temperature,
rel.humidity, rainfall))
A scatterplot of all variables may be constructed using the following command:
pairs(severity.mult)
Output
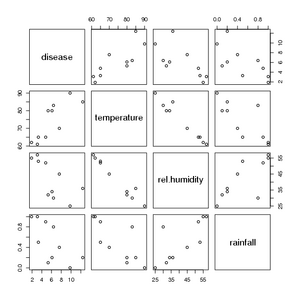
This produces the following scatterplot matrix illustrating the relationship between each pair of variables:
Click to enlarge.
The patterns illustrated in the graph indicate an approximately straight-line relationship between each pair of variables. A scatterplot is a useful tool to examine not only how the potential predictor variables possibly relate to the response, but to also provide an exploratory method to determine if predictor variables are associated with one another (i.e., multicollinearity).
Next we fit a multiple linear regression model to the data with disease as a response variable, and temperature, rel.humidity, and rainfall as predictor variables.
##Multiple regression model
severity.mult.lm <-
lm(disease~temperature+rel.humidity+rainfall,
data=severity.mult)
summary(severity.mult.lm) #summary of the linear model
These commands produce the following output:
Output
Residuals:
Min 1Q Median 3Q Max
-1.5630 -0.7119 -0.2576 0.3774 2.9775
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -74.9798 25.7954 -2.907 0.0271 *
temperature 0.7954 0.2342 3.396 0.0146 *
rel.humidity 0.5423 0.2037 2.663 0.0374 *
rainfall -1.2061 2.1027 -0.574 0.5871
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.563 on 6 degrees of freedom
Multiple R-Squared: 0.8415, Adjusted R-squared: 0.7623
F-statistic: 10.62 on 3 and 6 DF, p-value: 0.008172
In the output from this first analysis, the p-value for the full model is 0.008172, small enough to suggest that at least one of the predictor variables may be useful for prediction. The adjusted R2 is 0.7622 which indicates that the predictor variables explain 76% of the variance in the response variable. The next step is to address the apparent correlation between the predictor variables.
Multicollinearity
When using multiple linear regression, multicollinearity, or correlation among predictor variables, is an important consideration. When multicollinearity is a problem, standard errors for the estimates will tend to be large and parameter estimates may be illogical. One can calculate a variance inflation factor (VIF) for each independent variable, where a VIF of five or greater indicates the existence of multicollinearity. A function vif() is available in R version 2.4.1. and the car library (requires downloading of the package from CRAN). In our example, the VIF values were 22.9 for temperature, 21.3 for relative humidity, and 2.4 for rainfall. The scatterplots had shown that temperature and relative humidity were probably strongly related, which may explain such large VIF values. For more conclusions on multicollinearity and how to handle it, see Heiburger and Holland (2003). In the example given above, there is some indication of multicollinearity. One way to try to eliminate multicollinearity problems is by doing variable selection to select a subset of predictor variables that are not strongly correlated.
One method to select appropriate predictor variables, ones that are useful for prediction and not strongly correlated with each other, is backward elimination (Neter et al. 1996). In this approach, all predictor variables are included in the starting models, and then particular predictor variables are removed to iteratively search for the best fit. The Akaike information criterion (AIC) can be used to select among models for an optimal combination of parsimony (limiting the model to the smallest number of parameters needed) and good fit. A lower AIC indicates a better model.
step(severity.mult.lm)
Output
step(severity.mult.lm)
Start: AIC= 11.83
disease ~ temperature + rel.humidity + rainfall
Df Sum of Sq RSS AIC
- rainfall 1 0.804 15.467 10.361
14.662 11.827
- rel.humidity 1 17.326 31.988 17.628
- temperature 1 28.189 42.852 20.552
Step: AIC= 10.36 disease ~ temperature + rel.humidity
Df Sum of Sq RSS AIC
15.467 10.361
- rel.humidity 1 17.425 32.892 15.906
- temperature 1 33.031 48.497 19.789
Call:
lm(formula = disease ~ temperature + rel.humidity, data = severity.mult)
Coefficients:
(Intercept) temperature rel.humidity
-78.2751 0.8308 0.5438
This output indicates the steps taken to select the model. The first model tested includes all three predictor variables and the AIC for that model is calculated. Then the AIC for each model that excludes a single predictor variable is calculated. Excluding rainfall results in a lower AIC, so that model is selected in the next step. When either temperature or relative humidity are removed from that model, the AIC goes up, indicating that the best model includes temperature and relative humidity as predictors and excludes rainfall. The new model still has the issue of multicollinearity between the two predictors (temperature and relative humidity). Further considering may be given for other methods to deal with this effect, including Ridge or Bayesian regression models (Neter et al. 1996). In the next step illustrated below, this model is analyzed.
severity.mult.lm2 <- lm(disease~temperature+rel.humidity,
data=severity.mult)
summary(severity.mult.lm2)
Output
severity.mult.lm2 <- lm(disease~temperature+rel.humidity,data=severity.mult)
summary(severity.mult.lm2)
Call:
lm(formula = disease ~ temperature + rel.humidity, data = severity.mult)
Residuals:
Min 1Q Median 3Q Max
-1.2463 -0.5882 -0.2936 0.2904 3.2503
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -78.2751 23.9119 -3.273 0.01361 *
temperature 0.8308 0.2149 3.866 0.00616 **
rel.humidity 0.5438 0.1936 2.808 0.02621 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.486 on 7 degrees of freedom
Multiple R-Squared: 0.8328, Adjusted R-squared: 0.7851
F-statistic: 17.44 on 2 and 7 DF, p-value: 0.00191
Just as for simple linear regression (see Sparks et al., 2008), it’s important to check that the model assumptions are adequately met. The following code produces four plots to help in model evaluation. The plot function in R provides several types of diagnostic graphs that can be selected by changing the number called in which = _.
par(mfcol=c(2, 2)) #Sets the graphic to display all
# four plots in one window
plot(severity.mult.lm2, which=1) #residuals versus fitted
plot(severity.mult.lm2, which=2) #QQ plot
plot(severity.mult.lm2, which=3) #plot of square-root
# standardized residuals
# against fitted value
plot(severity.mult.lm2, which=5) #Residuals versus leverage plot
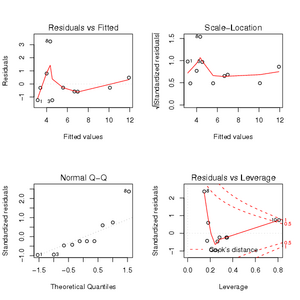
The four plots are of: (i) Residuals vs. fitted (or predicted) values, (ii) Scale-location (square-root of the standardized residual) vs. fitted values, (iii) Normal Quantile-Quantile (Q-Q) relation, and (iv) Residuals vs. leverage (influence of a single observation on model estimates).
Output
Click to enlarge.
Ideally the first two plots will show no relationship. A straight line in the Q-Q plot indicates a normal distribution for the residuals. Ideally the leverage of each observation would be equal. If Cook's distance is > 1 the observation may be considered an outlier. To obtain a summary of influential cases, using measures such as DFFITS, DFBETAS, and Cook's distance, there is a function called influence.measures that can be used with lm or glm objects (Neter et al. 1996).
The model can also be used to predict disease severity for new values of temperature and relative humidity. The following code produces the prediction for temperature = 95 and relative humidity = 30, along with confidence limits for the prediction.
new <- data.frame(temperature=95, rel.humidity=30)
#new temperature and new rel humidity
predict(severity.mult.lm2, newdata=new, interval="confidence")
Output
fit lwr upr
[1,] 16.96165 11.42027 22.50303
Application of maximum likelihood based methods for disease forecasting
With the development of more rapid computing technologies, it is possible to compute a large number of simulations to support new modeling methods for plant disease forecasting. The development of disease forecasting models is based on determining the value of unknown parameters for an appropriate model.
One method for estimation of parameters is maximum likelihood estimation (MLE), first developed by R.A. Fisher (Myung 2003). The basic idea behind MLE is that one can calculate the probability of observing a particular set of data given the model of interest and this is called the likelihood of a sample. The likelihood of observing the actual data for each of the potential parameter values is calculated to determine which set of parameter values maximizes the likelihood.
To illustrate the concept of MLE, let's examine a random sample from a binomial distribution with given parameter p. MLE is then used to determine the parameter estimate, as if there was no knowledge of the parameter. Finally, the parameter estimate based on MLE is compared to the true value.
Before getting into this example, some background on MLE is necessary. To begin, based on some prior knowledge, a model for the data may be developed, which may be defined as a probability distribution function, f. The likelihood, L, is defined as a function of the parameter(s) in the model given the data: L(θ|x). When the number of samples is > 1, the likelihood is a joint likelihood of observations. In practice, it is often easier computationally to work with the log-likelihood, defined as logL(θ|x). The logL is maximized by taking the first derivative with respect to the parameter in order to obtain the estimate of the parameter.
Consider a binomial sampling situation where a coin is tossed 10 times (in R: rbinom(10,1,0.5)). If using 1 to represent the heads and 0 to the tails of the coin, this is one possible outcome for those 10 events: 0 1 0 1 1 0 0 1 0 0.
Given this data, a natural question is: What is the probability that a head will be observed on the next toss? One approach may be to count the number of times that a head was observed in the initial probability experiment. Following this approach, given an observation of four heads out of 10 coin tosses, the probability of a head on the next toss may be 0.4. This probability may also be estimated using MLE as a simple example of the MLE method, assuming that the occurrence of heads follows a binomial distribution with a probability parameter p. Formally, Prob(x = 1) = p and Prob(x = 0) = 1 - p, where x is an observation. All 10 tosses of the coin are considered independent, such that the 10 observations x1, x2,...,x10 can be considered a random sample from a binomial distribution. The joint likelihood becomes:
L(x1, x2, ..., x3 | p)
= Prob(x1 = 0 | p) * Prob(x2 = 1 | p) *...* Prob(x10 = 0| p)
= (1 - p) * p * (1 - p) * p * p * (1 - p) * (1 - p) * p * (1 - p) * (1 - p)
= (1 - p)6 p4
and logL as
logL = 6log(1 - p) + 4 log( p)
Now, the goal is to maximize the logL function. This may be accomplished by taking the first derivative of logL with respect to p and setting it equal to zero. In this situation, an explicit solution for p is obtained as:
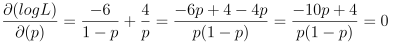
solving this equation, gives p = 0.4.
This implies that the probability of heads is 0.4. But how good is this estimate? For the example above, the observations were obtained from a random binomial distribution with probability p = 0.5. Does this imply that the MLE estimate is not useful? In this case the random sample was only of size 10, which is a fairly small sample. Sample size is an important consideration for use of MLE or other estimation methods for plant disease forecasting models. The smaller the number of observations, the bigger the difference between the estimate and the true parameters is likely to be.
Suggested Exercise
Determine the MLE estimate for the probability of heads and then compare it to p = 0.5.
1 0 1 1 1 0 0 0 0 1 1 0 0 1 0 0 1 0
1 1 1 0 1 0 0 0 0 1 1 1 0 1 0 0 1 0
1 1 0 0 1 0 0 1 1 0 0 1 0 1
In R, there are currently several libraries that enable development of logistic regression models using MLE, as well as development of expert systems (classification and regression trees and neural networks, for example). In the Stats library, generalized linear models can be fit using the glm function. Yuen (2006; http://www.apsnet.org/edcenter/advanced/topics/Pages/DerivingDecisionRules.aspx) discusses generalized linear models and shows how they may be fit using SAS in his document. Furthermore, the Design library offers regressions models, including logistic regression, Cox regression, accelerated failure time models, and others (Harrell 2001). Plant pathological examples using functions in the Design library include Esker et al. (2006). Paul and Munkvold (2004) used the Design library, as developed for S-Plus, by the same author.
For the purpose of this article, an examination of logistic regression will be handled using the glm function and to show how a model may be constructed and compared using the deviance values. For further information regarding logistic regression, consult Harrell (2001) or Agresti (2002). Briefly, however, logistic regression is applied to determine the probability that disease occurs as:
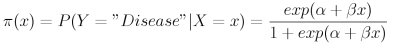
where x are predictor variables of interest and α and β represent logistic coefficients to be estimated (Agresti 2002).
#The glm function is available in the Stats library.
# For more information on glm, type: ?glm
#Example data where the event is presence or absence of disease
# (prevalence) (1=presence,0=absence), with associated air
# temperature over 3-months, a measure of maximum snowfall,
# and an indicator for whether the disease occurred the
# previous year. We might assume that favorable winter
# weather increases the survival of a pathogen. This
# information can be used to develop a model using logistic
# regression, which uses maximum likelihood to obtain the
# estimates of a parameter
prevalence=c(1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1,
1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1,
0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0,
1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0,
1, 0, 0, 0, 1, 1, 1)
month1=c(-6.15, -4.78, -5.47, -4.79, -4.94, -4.68, -5.05, -4.58,
-4.53, -4.78, -4.85, -5.31, -4.95, -4.18, -3.95, -4.53,
-4.12, -3.91, -5.25, -5.78, -5.18, -5.22, -4.48, -5.87,
-4.63, -4.32, -4.40, -4.16, -4.22, -2.89, -4.60, -5.70,
-5.72, -4.27, -4.24, -5.04, -6.39, -4.73, -5.69, -3.85,
-4.86, -4.55, -3.43, -5.58, -5.09, -4.40, -4.15, -3.65,
-4.56, -5.43, -3.23, -5.86, -5.47, -5.55, -5.31, -3.86,
-5.48, -4.44, -6.27, -4.84, -4.33, -5.07, -6.51, -5.51,
-4.79, -5.93, -4.04, -5.42, -5.16, -5.12, -5.01, -3.79,
-5.93, -6.43, -4.76)
month2=c(-8.52, -7.14, -7.99, -8.53, -6.76, -6.71, -8.27, -8.08,
-9.29, -6.03, -5.43, -6.36, -8.71, -7.57, -8.13, -6.99,
-8.40, -6.08, -9.01, -5.78, -7.48, -7.07, -6.88, -6.87,
-7.17, -9.07, -4.66, -10.05, -8.68, -7.73, -9.49, -6.85,
-6.51, -7.47, -7.96, -10.65, -7.62, -7.14, -8.38, -7.01,
-7.02, -6.65, -7.34, -7.50, -8.90, -8.80, -9.12, -8.13,
-8.79, -8.09, -5.58, -5.46, -7.72, -8.22, -6.96, -5.55,
-8.60, -8.88, -8.47, -8.55, -7.89, -9.25, -7.44, -9.06,
-7.50, -8.05, -7.52, -7.85, -9.33, -8.72, -7.12, -9.40,
-9.76, -8.41, -8.79)
month3=c(-5.09, -3.84, -5.24, -3.89, -5.22, -5.60, -5.14, -2.62,
-2.44, -4.86, -5.46, -3.20, -5.35, -4.04, -3.78, -5.03,
-4.66, -5.46, -3.59, -3.80, -4.10, -3.17, -2.72, -4.32,
-5.69, -4.23, -3.83, -6.20, -6.12, -2.05, -4.41, -4.75,
-4.13, -4.95, -4.33, -5.83, -4.73, -4.66, -3.41, -2.53,
-5.41, -5.39, -5.87, -6.87, -4.99, -5.27, -5.88, -5.16,
-4.72, -3.80, -2.98, -4.23, -4.69, -2.31, -5.03, -3.40,
-2.79, -2.81, -3.98, -5.13, -4.77, -3.85, -3.97, -2.70,
-4.21, -2.82, -5.47, -3.57, -4.53, -4.39, -3.47, -4.35,
-3.56, -5.42, -3.38)
maximum.snow=c(163, 201, 213, 183, 169, 197, 136, 180, 137, 168,
189, 168, 172, 238, 170, 183, 212, 157, 184, 245,
247, 148, 151, 166, 153, 212, 197, 202, 227, 153,
237, 195, 208, 223, 174, 219, 217, 128, 119, 177,
111, 175, 136, 186, 200, 197, 159, 227, 246, 194,
247, 222, 160, 247, 172, 217, 194, 222, 168, 243,
157, 229, 149, 185, 211, 178, 225, 193, 201, 202,
212, 154, 196, 272, 152)
previous.prevalence=c(0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0)
#Create a dataframe
example.forecasting=
as.data.frame(cbind(prevalence, month1, month2, month3,
maximum.snow, previous.prevalence))
#Begin by considering a model with the air temperature for
# month1 as the only predictor of prevalence
model1=glm(prevalence~month1, family=binomial,
data=example.forecasting)
summary(model1)
Output
Call:
glm(formula = prevalence ~ month1, family = binomial, data = example.forecasting)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.301 -1.230 1.010 1.135 1.275
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.7501 1.5077 -0.498 0.619
month1 -0.1812 0.3057 -0.593 0.553
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 103.64 on 74 degrees of freedom
Residual deviance: 103.28 on 73 degrees of freedom
AIC: 107.28
Number of Fisher Scoring iterations: 3
#To determine if month1 is a useful predictor, we can perform a
# deviance test, which compares the residual deviance with the
# parameter added to the null deviance. Here, this is
# 103.64-103.28 with 1 df and is a chi-square test.
1-pchisq(103.64-103.28,1)
Output
1-pchisq(103.64-103.28,1)
[1] 0.5485062
#We can pick a particular model, but also may use the step
# function to compare models and select the model with the
# best fit:
step(glm(prevalence~1,
data=example.forecasting,
family=binomial),
scope=list(lower=~1,
upper=~month1*month2*month3*
maximum.snow*previous.prevalence),
direction='forward')
Output
Start: AIC= 105.64
prevalence ~ 1
Df Deviance AIC
+ previous.prevalence 1 86.557 90.557
103.638 105.638
+ month3 1 102.206 106.206
+ month1 1 103.285 107.285
+ maximum.snow 1 103.413 107.413
+ month2 1 103.530 107.530
Step: AIC= 90.56
prevalence ~ previous.prevalence
Df Deviance AIC
+ month1 1 82.930 88.930
86.557 90.557
+ month2 1 84.622 90.622
+ maximum.snow 1 86.394 92.394
+ month3 1 86.557 92.557
Step: AIC= 88.93
prevalence ~ previous.prevalence + month1
Df Deviance AIC
+ month2 1 80.784 88.784
82.930 88.930
+ maximum.snow 1 82.659 90.659
+ month3 1 82.688 90.688
+ month1:previous.prevalence 1 82.930 90.930
Step: AIC= 88.78
prevalence ~ previous.prevalence + month1 + month2
Df Deviance AIC
80.784 88.784
+ month3 1 80.344 90.344
+ maximum.snow 1 80.726 90.726
+ month1:month2 1 80.783 90.783
+ month1:previous.prevalence 1 80.784 90.784
+ month2:previous.prevalence 1 80.784 90.784
Call: glm(formula = prevalence ~ previous.prevalence + month1 + month2,
family = binomial, data = example.forecasting)
Coefficients:
(Intercept) previous.prevalence month1
-6.9184 19.8306 -0.7426
month2
-0.3709
Degrees of Freedom: 74 Total (i.e. Null); 71 Residual
Null Deviance: 103.6
Residual Deviance: 80.78 AIC: 88.78
Here forward selection was used to select the best model; that is, the simplest model was evaluated and predictor variables were added if they improved the fit using the AIC as criterion. Based on the above output, the following is a potential forecasting model
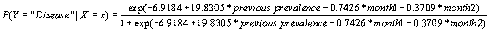 .
.
Click to enlarge
Suggested Exercise
When model1 was entered initially and its deviance was determined (e.g., the reduction in log-likelihood from the null model), it appeared that this explanatory variable did not improve the model. However, when using the stepwise procedure, this variable was selected for inclusion in the best model. From this, consider the development of a forecasting model where variables are added individually and compared, as well as a forecasting regression model based on a backwards selection procedure. Do you obtain the same models? The following R code can be used for performing a backward selection procedure.
step(glm(prevalence~month1*month2*month3*maximum.snow*
previous.prevalence,
data=example.forecasting,
family=binomial),
scope=list(lower=~1,
upper=~month1*month2*month3*maximum.snow*
previous.prevalence),
direction='backward')
Next, an introduction to plant disease forecasting